
"이 포스팅은 쿠팡 파트너스 활동의 일환으로, 이에 따른 일정액의 수수료를 제공받습니다."
오늘이군
초등학생도 이해 할 수 있는 인공지능 머신러닝 딥러닝 (4차산업혁명 2부 / 인공지능 #2) 본문

머신러닝을 통해서 아파트 매매 가격에 대한 예측에 대한 논문이 있어서 살펴보았습니다

요약 부분을 살펴보니
데이터를 수집해서 인공지능 기술을 활용하여 아파트 가격을 예측한다는 내용인데요
기계학습 알고리즘을 사용하였고 정확도는 95.1%라고 합니다
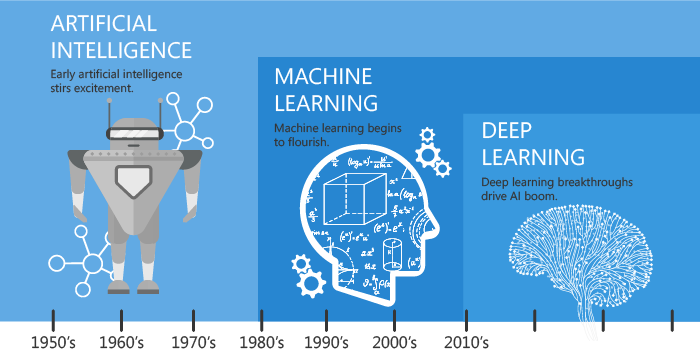
오늘은 여기서 사용된 기계학습. 즉 머신러닝과 딥러닝에 대해서 알아보면서
인공지능에 대해 좀 더 이해하는 시간을 가져 보고
더 나아가서 어떤 회사에 투자를 해야 하는지 생각해보는 시간을 갖도록 하겠습니다.
인공지능, 머신러닝, 딥러닝 머리 아픈 주제라고 생각될 수 있지만
생각보다는 어려운 개념이 아니니 차근차근 들어보시기 바랍니다.

일반적인 프로그래밍 시대에는
사용자가 컴퓨터에게 입력 값을 주면, 컴퓨터는 프로그램에 의해서 결과 값을 주게 됩니다.

예를 들어 곱하기를 해주는 프로그램이 있다면
이 프로그램에게 2와 3을 입력값으로 주면 결과로 2*3의 결과인 6을 얻을 수 있습니다.
사람이 일일이 프로그래밍을 해줘야 하기 때문에
프로그래밍을 만들고 유지 보수하는데 비용이 들게 되며,
특히 시간이 많이 소요되기 때문에 급변하는 세상에 따라가기 어려운 단점이 있었습니다.

머신러닝이 나오고 나서 이 개념은 바뀌게 되었는데요,
컴퓨터에게 입력 값과 결과 값을 주면, 데이터로부터 의사결정을 위한 패턴을 기계가 스스로 학습하게 됩니다.

예를 들어 다음과 같은 데이터 입력 값과 결과 값이 있다면
컴퓨터가 데이터를 보고 스스로 학습을 해서 프로그래밍을 하게 되는 것입니다.
이런 머신러닝은 학습방법에 의해 총 3가지로 분류가 되는데요

첫 번째, 지도 학습(Supervised Learning)입니다.
지도 학습은 입력 값과 출력 값을 모두 확인해서
데이터의 특징을 파악하고, 파악된 특징을 토대로 다음 출력 값을 예측합니다
실생활로 예를 들자면, 쇼핑몰에서 어떤 광고를 보내야 할지 고민한다고 하면

A라는 20대 여성은 새로운 아이폰을 샀고,
B라는 60대 여성은 새로운 아이폰을 봤지만 안 샀고
C라는 다른 60대 여성은 새로운 아이폰을 봤지만 안 사고, 갤럭시를 샀다
라는 데이터가 있다고 하면
컴퓨터는 이 데이터를 통해서

B에게는 새로운 갤럭시에 대한 광고를 보내는 등의
패턴을 학습할 수 있다는 것입니다.

두 번째, 비지도 학습(Unsupervised Learning)입니다.
비지도 학습은 입력 값 만으로(label이 없다) 비슷한 데이터들을 묶는데 효과적입니다.

예를 들면, SNS에 고객/팔로우/팔로워 정보를 가지고,

새로운 친구를 추천해줘서 예전에 친구를 만날 수 있게 해 주고, SNS에 좀 더 머물게 하는 효과를 얻을 수 있습니다.

세 번째, 강화 학습 (Reinforcement Learning)입니다.
강화 학습은 상과 벌이라는 보상(reward)을 주며 보상을 최대화하도록 학습합니다.
예를 들면 넷플릭스나, 유튜브의 알고리즘은
좋아요나 싫어요 라는 보상을 받으며 학습하여
우리가 재미있을 만한 콘텐츠를 추천하면서 앱을 끄지 않게 만들곤 합니다.

이렇게 살펴본 머신러닝은 어떤 데이터를 분류하거나, 값을 예측하는 데에 효과 적입니다.
이렇게 데이터의 값을 잘 예측하기 위한 데이터의 특징들을 "Feature"라고 부르며,
머신러닝에서는 적절한 Feature를 잘 정의하는 것이 핵심입니다.

아주 간단한 예시였지만 스마트폰을 구매하는 데에는
성별과 나이가 영향을 끼칠 수 있다고 판단하여
Feature 엔지니어가 직접 성별과 나이를 Feature로 정의하는 것입니다.

이렇게 딥러닝 이전의 머신러닝에서는 가공되지 않은 (raw) 데이터를 보고 사람이 직접 적절한 Feature를 만들어야 하는 불편함이 있었습니다.

하지만 딥러닝이 나오고 나서는
가공되지 않은 (raw) 데이터를 딥러닝 모델에 넣어주면 모델이 알아서 Feature를 알아내고 아웃풋을 내는 형식으로 발전하게 되었습니다.
즉, 딥러닝의 경우에는 'Feature'를 선정하는 부분까지 한꺼번에 학습합니다.
예를 들어 고양이를 구분한다고 하면
머신러닝에서는 귀의 형태, 입의 구조, 수염 유무, 털의 형태 등의 'Feature'를 사람이 먼저 선택해야 했지만

딥러닝의 경우 동물을 찍은 사진을 입력으로 넣어주면, 스스로 어떤 특징이 동물의 종류를 추정하는 데에 유용한 지 알아내게 됩니다.
이렇게 딥러닝은 Feature를 선정해줘서 사람의 손이 필요한 부분들을 컴퓨터가 더 많이 처리해주는 편리함이 있습니다.
그럼, 오늘의 결론입니다.

세상에는 다양한 일이 생깁니다.
사람의 경험에는 한계가 있지만

수많은 데이터를 학습한 인공지능은 사람보다 더 이성적으로 정확한 판단을 하게 될 것입니다

결국 좋은 프로그램은 다양한 데이터에서 나오게 될 것이고
우리는 데이터를 많이 가진 회사에 투자하는 것이 성공 확률을 높일 수 있다고 생각합니다.
그럼, 오늘도 감사합니다.
'오늘의 재테크 > 4차산업혁명' 카테고리의 다른 글
| 초등학생도 이해 할 수 있는 빅데이터 (4차산업혁명 3부) (0) | 2022.03.07 |
|---|---|
| 인공지능이 가져다 줄 세상의 변화 (인공지능 #1) (0) | 2022.02.15 |
| 클라우드 컴퓨팅 아주 쉽게 살펴보기 (4차산업혁명 1부 / 아마존 aws, 마이크로소프트 azure) (0) | 2022.01.30 |


